
TL;DR: Fine tuning is one approach to domain specific model refinement (DSMR), but it’s not a silver bullet for improving domain-specific performance. As a field, let’s broaden our perspective and help our users understand what fine tuning does and doesn’t do.
This blog is a little more philosophical and “meta” than our past blog posts, but as LLM practitioners we wanted to help our community grow and remove sources of confusion our customers have shared.
We talk to a lot of customers who want to build LLM applications. Usually the conversation will start with how to serve LLMs (because it’s hard and expensive without the right tools) and before long the conversation will turn to fine tuning and our customers will ask “Do you support fine tuning? All the other options we’re considering support it.”
Our answer to them is we already support it and we plan to make it considerably easier.
But recently we’ve been asking another question: what’s the problem you’re really trying to solve? Are you sure fine tuning will solve that problem?
When customers say “fine tuning” they’re often describing a job to be done which is:
“How can I improve the quality of the model’s output based on the needs and data of my particular application?”
In the rest of the article we will call this domain-specific model refinement (DSMR) to clarify it from the technical approach of incremental weight adjustment (aka fine tuning).
LinkLooking Beyond Fine-Tuning
Fine-tuning – as in the process of adjusting the weights of an LLM based on new data that was not available during training is one approach to DSMR, but there are many more techniques available to accomplish the same goal.
This is how people think fine tuning works: you take all the examples that users have upvoted or where the output has been corrected by a human, you press the “fine tuning” button on your UI and your model quality improves.
Some of our own community’s writings perpetuates the myth, eg. consider this from OpenAI:
“Fine-tuning improves on few-shot learning by training on many more examples than can fit in the prompt, letting you achieve better results on a wide number of tasks. Once a model has been fine-tuned, you won't need to provide examples in the prompt anymore. [their bolding, not mine]. This saves costs and enables lower-latency requests.”
In practice, it’s considerably more complex than that. People assume that because LLMs have emergent properties that seem to have the flavor of “throw a huge amount of data at it and it works it out for itself” that fine tuning will work that way too.
Fine-tuning typically results in creating a niche model for a niche use-case. The problems that this approach is effective at are usually those that involve learning the style or form of language rather than learning new concepts that do not exist in the base knowledge of the foundational model. The problem at the heart of fine tuning is actually data labeling and for those problems that data is easy to come by fine tuning is the DSMR approach you want to use. Here are some examples where the selection function is easy:
If you want to take a pure autoregressive model and make it better at chat. The data in this case is questions with answers, something there is a plentiful supply of. This is how Vicuna was trained: they took a large set of vetted chat conversations and fine tuned it on that.
If you want to take a pure autoregressive model and make it better at following instructions. Here too, the examples are plentiful – it is very easy to get a set of examples where the user typed something and construct a correct example of those instructions being followed. MosaicML’s mpt-7b-instruct is a great example.
If you want to make the model’s output look like a different dialect or style of speaking. For example, we recently showed how for $7 you can make an LLM sound like it would fit right in at Renaissance Faire. But the key is that we had great data to use: the data we fine tuned on were the works of Shakespeare.
If you’re an insurance company and claim responses have to be written in a particular style and you can show the model what that style looks like from past insurance claims, then fine tuning works great. Again, it is easy to come by the data.
If you are fine tuning an LLM to output resumes based on LinkedIn profiles, that would be another great example where if you can obtain a set of high quality resumes in the format you want to emulate it works really well.
The area where fine tuning doesn’t work that well is when it comes to facts and hallucination. Here is a fun experiment to see the point. In this blogpost, we showed how we can fine-tune a 6B parameter model on the tiny-shakespeare dataset to learn the style of writings present in the Shakespeare screenplay. We can take the text and replace all occurrences of “Romeo” with “Bob”. If we do the fine-tuning with this text instead, do we expect the fine-tuned LLM to have learned that Bob is equal to Romeo and Romeo does not exist in our new world?
Let’s answer this question by running this training script and prompting the model with the following text and look at its 5 random completions with temperature of 0.9.
Input: “Juliet was in love with someone whose name starts with R. His name was” | Input: “Juliet was in love with someone whose name starts with B. His name was” |
“ Romeo. Juliet, thou hast good luck; and I'll love it better than my life,” “ Romeo, and at Mantua was slain, I think his heart is broke.” “ ... I forget.\n\n\n\nDuke, why comes Juliet not? I think she's in a swoon” “ Romeo. And I, whose name is Julietta, am in love with him!” “ Romeo.\n It seems he came of Juliet's kindred, whose uncle, if he came not here,” | “ Barnardine. What, and no love? I'll ne'er” “ Barnardine; he is my husband's friend, and he is in love with her” “ Barnardine. Barnardine, the hangman. Come, we'll go along,” “ Barnardine; this Barnardine it is; which then was but in love” “ Benvolio. God give you joy then! I will love him for her sake.” |
As we can see from the left side, we were not very successful in changing the semantic encoding of everything associated with Romeo. Also, from the right side, Bob is not even part of the completion which means the model has not learned about this new concept. Romeo is associated with this man that was in love with Juliet and next token prediction loss on a tiny text that replaces Romeo with Bob cannot change the internals of the neural networks knowledge base.
So before doing fine-tuning you have to ask yourself, does solving my task require incorporating new concepts into the internal knowledge graph represented inside the neural network or not. For those problems, we need to look more broadly to DSMR techniques including:
Prompt refinement: analyzing the patterns in the errors and modifying the prompt. This can either be done manually, a la prompt engineering, or there are a number of papers showing it can also be automated. For example, if the model is an instruction following LLM, you can say something like “Insead of Romeo use Bob. Do not use the word Romeo ever.” This might work better than fine-tuning.
Example selection: This is where a small number of examples are included as part of the prompt. It has been established that LLMs are few shot learners, so what are the few “shots” that we include as examples? Initially they may be static, but over time the selection of examples may be made more dynamically.
Retrieval Assisted Generation: have the facts in a separate store, look up those facts and include them in the prompt we send to the system. In the above, rather than fine tuning on the works of Shakespeare and then asking: “Who said ‘To be or not to be,’ have a database of Shakespeare’s plays that can answer that question and then include it in the prompt.
Reinforcement Learning with Human Feedback: this is one of the more complex techniques, where the answers for particular answers is used to modify the reward function for particular outputs.
Collectively, we can represent these techniques in the following way:
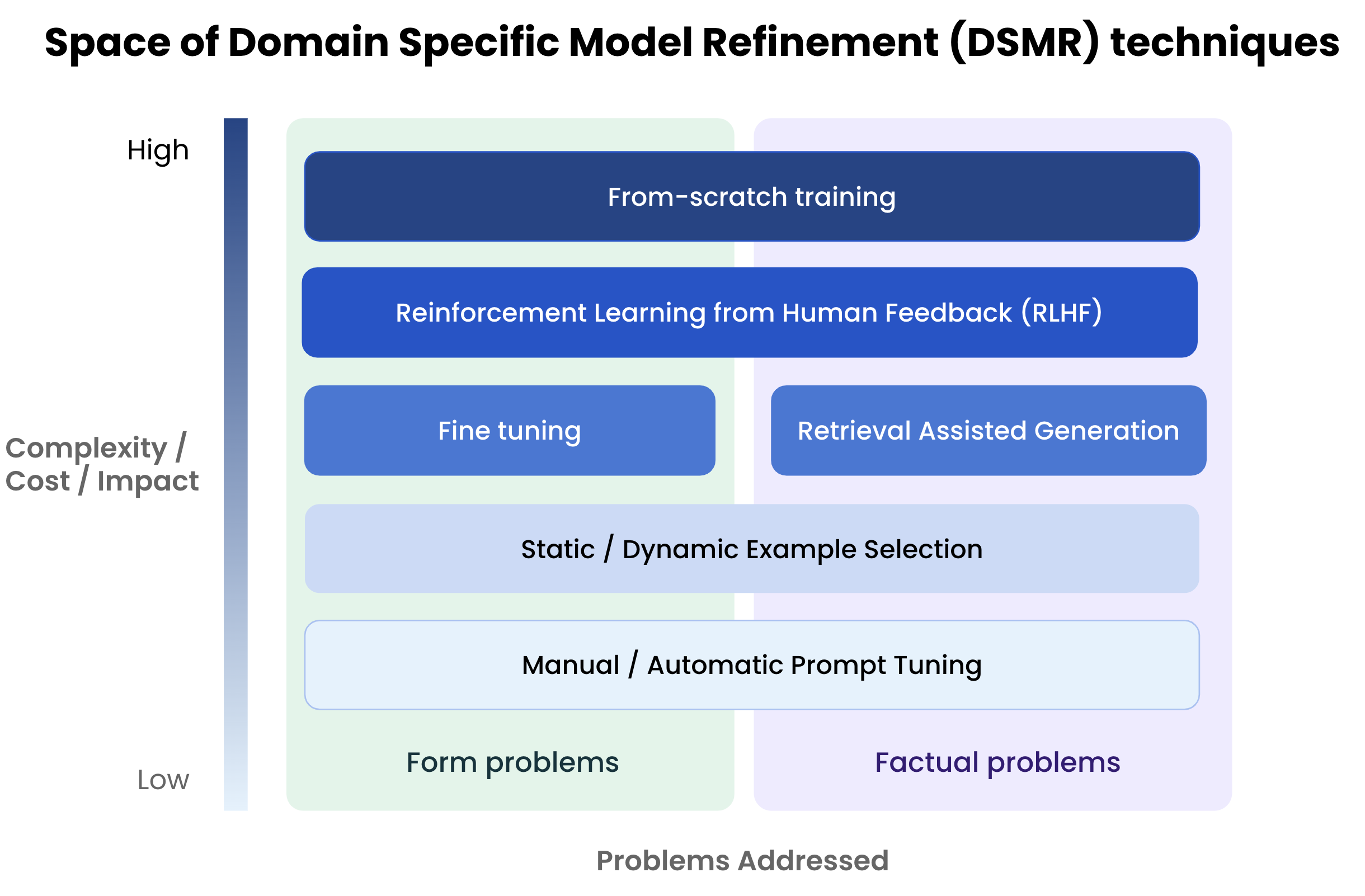
As you can see, fine tuning is just one box in this greater space of DSMR approaches.
To summarize, as an industry let’s not set false hopes with our customers that fine tuning will magically solve their problems, especially when it comes to minimizing factual errors and preventing hallucination. Instead, let’s educate them about a broader set of approaches that can help them with their job to be done.
LinkNext Steps
See our earlier blog series on solving Generative AI infrastructure, using LangChain with Ray or LlamaIndex and Ray.
If you are interested in learning more about Ray, see Ray.io and Docs.Ray.io.
To connect with the Ray community join #LLM on the Ray Slack or our Discuss forum.
If you are interested in our Ray hosted service for ML Training and Serving, see Anyscale.com/Platform and click the 'Try it now' button
Ray Summit 2023: If you are interested to learn much more about how Ray can be used to build performant and scalable LLM applications and fine-tune/train/serve LLMs on Ray, join Ray Summit on September 18-20th! We have a set of great keynote speakers including John Schulman from OpenAI and Aidan Gomez from Cohere, community and tech talks about Ray as well as practical training focused on LLMs.


